
一、什么是数据描述统计分析?
简单而言,描述性统计分析是用几个关键的数字来描述数据集的整体情况<集中性和离散型(波动性大小)>。
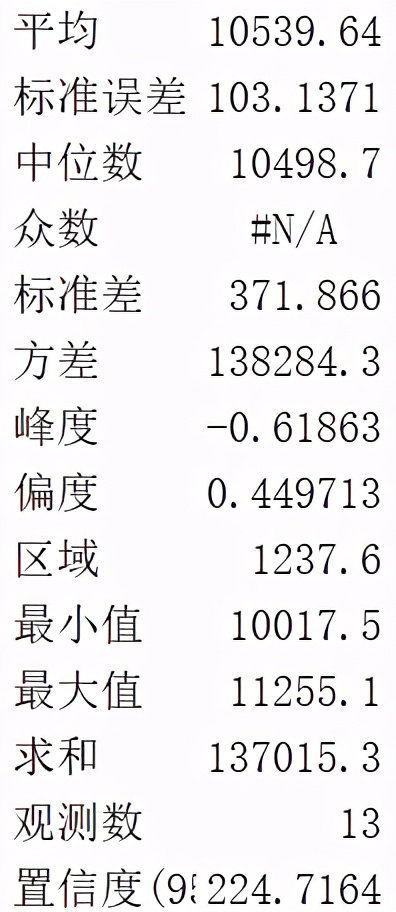
描述数据集常用4个指标:平均值 四分位数 标准差 标准分,利用这些指标可以进行数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形。
通常我们拿到一份数据集,首先对获取的数据进行清洗,整理成我们业务所需要的新数据,然后再对新数据进行描述性统计分析,常用的是 Excel 中自带的分析分析工具(描述性统计分析),Excel加载后即可使用。

二、描述统计分析常用指标
01 – 均值
均值容易受极值的影响,当数据集中出现极值时,所得到的的均值结果将会出现较大的偏差。
02 – 中位数
数据按照从小到大的顺序排列时,最中间的数据即为中位数。
当数据个数为奇数时,中位数即最中间的数,如果有N个数,则中间数的位置为(N+1)/2;当数据个数为偶数时,中位数为中间两个数的平均值,中间位置的算法是(N+1)/2。中位数不受极值影响,因此对极值缺乏敏感性。
03 – 众数
数据中出现次数最多的数字,即频数最大的数值。众数可能不止一个,众数不能能用于数值型数据,还可用于非数值型数据,不受极值影响。
04 – 极差
极差=最大值-最小值,是描述数据分散程度的量,极差描述了数据的范围,但无法描述其分布状态。且对异常值敏感,异常值得出现使得数据集的极差有很强的误导性。
05 – 四分位数
数据从小到大排列并分成四等份,处于三个分割点位置的数值,即为四分位数,四分位数分为上四分位数(数据从小到大排列排在第75%的数字,即最大的四分位数)、下四分位数(数据从小到大排列排在第25%位置的数字,即最小的四分位数)、中间的四分位数即为中位数。四分位数可以很容易地识别异常值。(一般通过箱线图表示数据更直观)
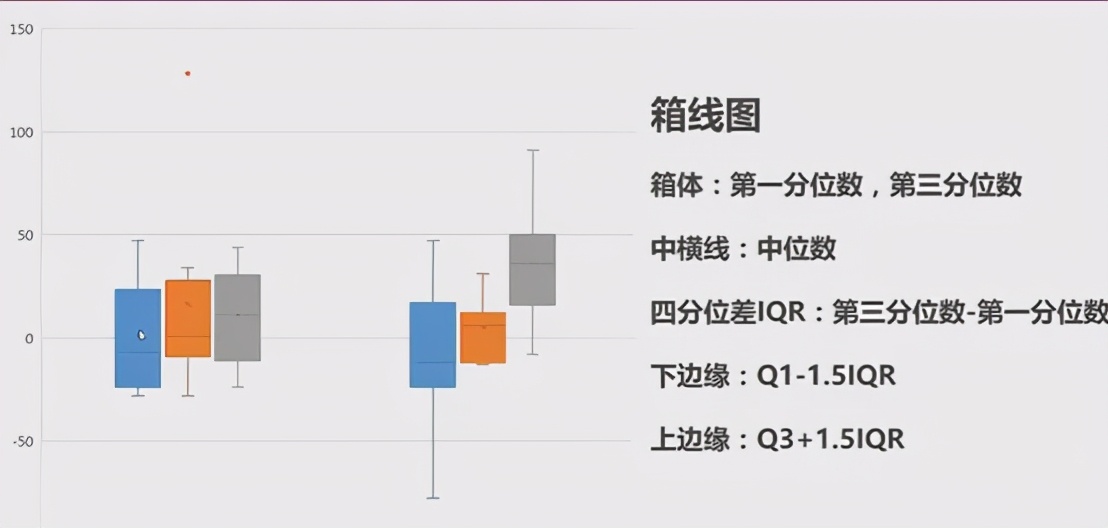
在上下边缘之外的数据一般认为是异常值。
06 – 标准差
标准差(Standard Deviation),也称均方差(mean square error),是各数据偏离平均数的距离的平均数,它是离均差平方和平均后的方根,用σ表示。标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。
- 标准差越大,波动越大,平均数相同的,标准差未必相同。
- 标准差可以反映平均数不能反映出的东西(比如稳定度等)。
Excel中有STDEV,STDEVP;STDEVA,STDEVPA四个函数,分别表示样本标准差、总体标准差;包含逻辑值运算的样本标准差、包含逻辑值运算的总体标准差
在计算方法上的差异是:
- 样本标准差=(样本方差/(数据个数-1))^2
- 总体标准差=(总体方差/(数据个数))^2。
07 – 标准分
标准分又叫标准差的标准化值,每个数据距离平均值多少个标准差。标准分布又称正太分布。
切比雪夫定理2.0正态分布中,至少有68%的数据,位于平均数1个标准差范围内。正态分布中,至少有95%的数据,位于平均数2个标准差范围内。正态分布中,至少有99.8%的数据,位于平均数3个标准差范围内。

三、统计概率思维
概率思维:
1、如果要求的是若干事件中”至少”有一个发生的概率,则马上联想到概率加法公式;当事件组相互独立时,用对立事件的概率公式;
2、若某事件是伴随着一个完备事件组的发生而发生,则马上联想到该事件的发生概率是用全概公式计算;若一个完备事件组的发生而发生,则马上联想到该事件的发生概率是用全概公式计算;
3、凡求解各概率分布已知的若干个独立随机变量组成的系统满足某种关系的概率(或已知概率求随机变量个数)的问题,马上联想到用中心极限定理处理。
四、统计概率常用
01 – 贝叶斯定律模型
对于由证据的积累来推测一个事物发生的概率具有重大作用, 它告诉我们当我们要预测一个事物, 我们需要的是首先根据已有的经验和知识推断一个先验概率, 然后在新证据不断积累的情况下调整这个概率。整个通过积累证据来得到一个事件发生概率的过程我们称为贝叶斯分析。

02 – 二项分布
二项分布是一种离散型的概率分布。二项代表特有两种可能的结果,把一种称为成功,另一种称为失败,每次试验成功和失败的概率是相沟通的,每次试验互相独立。例如:抛硬币。
03 – 泊松分布
主要踊跃轨迹某事件在特定时间或空间中发生的次数,比如一天内中奖的个数,一个月内某机器损坏的次数等。
描述性统计分析是属于统计学中比较小的一个理论知识,但是在日常的数据分析中,能够快速地让我们对一份数据进行了解,并能够通过科学的图表展示,发现数据规律,进行未知数据的预测。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至605152901@qq.com 举报,一经查实,本站将立刻删除。
